최근 GPGPU를 이야기함에 있어서 빠지지 않고 등장하는
CUDA에 대해서 알아보자
집에서 또는 연구실에서 사용하고 있는 Desk Top 컴퓨터에 그래픽 카드 한 장을 추가함으로 인해서 계산 및 Simulation 속도가 200배가 빨라 진다면 과연 사람들은 이 기술을 어떻게 받아 들일까?
엔비디아는 CUDA(Compute Unified Device Architecture)라는 기술을 2006년 10월 웹에서 공개하면서 본격적으로 개인용 슈퍼 컴퓨터의 시대를 열어가려고 하고 있다.
오늘날의 GPU는 High Performance Computing(HPC)에 있어서 가장 적합한 솔루션이라고 평가되고 있으며 세상에서 가장 빠르게 확산이 되고 있는 기술 중에 하나이다. 특히 학술, 계산 분야에 있어서의 Heterogeneous Computing을 통해 시스템을 최적화함으로써 CPU는 Operating System, Task 처리와 같은 순차적인 업무를 위주로, GPU는 Massive한 Data를 처리하게 된다. GPU는 CPU대비 10배 가까운 메모리 인터페이스 Speed와 240개의 Core에서 동시에 Data를 처리함으로써 최대 200배 이상까지도 계산 속도를 높일 수 있으며 또한 시스템을 최적화 시킬 수 있다.
CUDA ("Compute Unified Device Architecture", 쿠다)는
그래픽 처리 장치(GPU)에서 수행하는 (병렬 처리) 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술이다.
CUDA는 엔비디아가 개발해오고 있으며 이 아키텍처를 사용하려면 엔비디아 GPU와 특별한 스트림 처리 드라이버가 필요하다. CUDA는 G8X GPU로 구성된 지포스 8 시리즈급 이상에서 동작한다. CUDA는 CUDA GPU 안의 명령셋과 대용량 병렬 처리 메모리를 접근할 수 있도록 해 준다.
개발자는 패스스케일 오픈64 C 컴파일러로 컴파일 된 '쿠다를 위한 C' (C언어를 엔비디아가 확장한 것) 를 사용하여 GPU 상에서 실행시킬 알고리듬을 작성할 수 있다.
쿠다 구조의 계산 인터페이스
쿠다 구조는 일련의 계산 인터페이스를 지원하며 이에는 OpenCL, DirectX Compute가 포함된다. C 언어가 아닌 다른 프로그래밍언어에서의 개발을 위한 래퍼(Wrapper)도 있는데, 현재 파이썬, 포트란, 자바와 매트랩 등을 위한 것들이 있다.
쿠다의 전망
쿠다를 통해 개발자들은 쿠다 GPU 안 병렬 계산 요소 고유의 명령어 집합과 메모리에 접근할 수 있다. 쿠다를 사용하여 최신 엔비디아 GPU를 효과적으로 개방적으로 사용할 수 있다. 그러나 CPU와는 달리 GPU는 병렬 다수 코어 구조를 가지고 있고, 각 코어는 수천 스레드를 동시에 실행시킬 수 있다. 응용 프로그램이 수행하는 작업(계산)이 이러한 병렬처리연산에 적합할 경우, GPU를 이용함으로써 커다란 성능 향상을 기대할 수 있다.
쿠다 적용
컴퓨터 게임 업계에서는 그래픽 랜더링에 덧붙여, 그래픽 카드를 게임 물리 계산 (파편, 연기, 불, 유체 등 물리 효과)에 사용된다.
쿠다는 그래픽이 아닌 응용 프로그램, 즉, 계산 생물학, 암호학, 그리고 다른 분야에서 10배 또는 그 이상의 속도 혜택을 가져왔다. 이 한 예는 BOINC 분산 계산 클라이언트 이다.
쿠다는 저수준 API와 고수준 API 모두를 제공한다. 최초의 CUDA SDK는 2007년 2월 15일에 공개되었으며 마이크로소프트 윈도와 리눅스를 지원했다. 맥 OS X지원은 2.0 버전에 추가되었다.
쿠다의 장점
1. 흩뿌린 읽기 - 코드가 메모리의 임의 위치에서 데이터를 읽을 수 있다.
2. 공유 메모리 - 쿠다는 고속 공유 메모리 지역 (16 또는 48KB 크기) 을 드러내어 스레드 간에 나눌 수 있게 해 준다. 이는 사용자 관리 캐시로 사용될 수 있는데, 텍스처 룩업을 이용하는 경우 보다 더 빠른 대역폭이 가능해진다.
3. 디바이스 상의 읽기, 쓰기가 호스트보다 더 빠르다.
4. 정수와 비트 단위 연산을 충분히 지원한다. 정수 텍스처 룩업이 포함된다.
쿠다의 예

쿠다의 제한
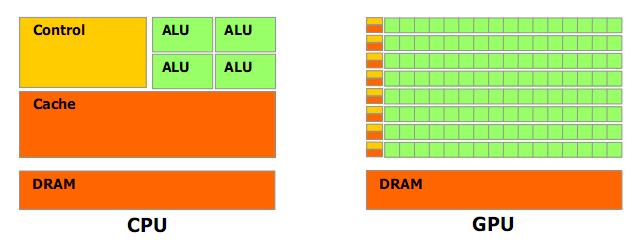
CPU와 GPU의 개념적 차이
CUDA 컴파일 환경
컴파일 워크플로우

기존의 개발환경에서는 GPGPU를 위해서 C/C++에서 그래픽 하드웨어를 컨트롤 하기 위해 Cg, DirectX, OpenGL 등의 쉐이더 명령어를 사용해야 한다. 이러한 방법의 단점은 그래픽에 대한 API의 복잡성으로 인하여 쉽게 프로그래밍 하기 어렵다는 단점이 있다. CUDA는 이러한 단점을 해결하기 위한 방법인데, 이를 위해 좀더 쉬운 명령어 셋을 C언어에 추가하고, 추가된 명령어는 NVCC를 통해 GPU컨트롤이 가능한 Assemble 코드인 PTX인 Assemble 코드로 변환하여 사용할 수 있도록 한다.
이러한 과정은 복잡해 보일 수 있는데, C언어 기반의 기존 컴파일러와 CUDA 명령어를 컴파일 할 수 있는 NVCC 컴파일러 두 개가 각 시스템에 맞는 오브젝트 파일이 만들어지고, 최종 결과물은 하나의 실행파일이 만들어 진다. 여기서 cudafe는 CUDA Front End의 약자로 사용되었다.
CUDA는 C/C++에 확장된 명령어 셋이다. 표준 C/C++ 이외의 CUDA만의 Syntax가 존재하는데, 이는 기존 C Compiler에서는 작동하지 않고 NVCC에서만 인식하여 컴파일하게 된다. 명령어 확장 셋으로는 크게 4가지로 나뉘는데, Kernel 실행 시 사용되는 Triple Bracket, 함수 관리 선행어, 메모리 관리 선행어, CUDA 내장 구조체와 변수들이다.
CUDA 병렬처리의 간단한 샘플
|
#include <stdio.h> __global__ void arrtest(int *d_a) for(a=0;a<5;a++) size_t memsize=5*5*sizeof(int); for(i=0;i<25;i++) dim3 dimgrid(1,1); scanf("%d ",&i); cudaFree(d_a); |
CUDA Documents
http://docs.nvidia.com/cuda/index.html
CUDA Toolkit
https://developer.nvidia.com/cuda-toolkit-31-downloads
CUDA 관련 영상
[출처] CUDA : 병렬처리 간단한 테스트|작성자 정백작
[출처] CUDA 병렬 프로그래밍|작성자 치국바보
위키피디아youtube
'Computer Graphics' 카테고리의 다른 글
| 지오데식 돔이란(geodesic dome) 지오데식 돔 2V (2) | 2014.02.11 |
|---|---|
| OpenCL이란 (0) | 2014.01.22 |
| 컴퓨터 그래픽스 GPU GPGPU (0) | 2014.01.15 |
| OpenGL 광원 조명 질감 설정 (0) | 2014.01.14 |
| 쉐이딩(Shading) 셰이딩 (0) | 2014.01.10 |